智能营销笔记本服务商
营销笔记本+万能采集+AI名片+智能电销+短信群发=同步管理
免费咨询热线: 15064770313

营销笔记本+万能采集+AI名片+智能电销+短信群发=同步管理
免费咨询热线: 15064770313
资料参考《曲阜市智程网络科技有限公司》致力于大数据智能营销笔记本的升级与售后。涵盖网站建设APP开发,企业软件定制化服务,
性能主要由代码的算法决定。没有这个问题。一些用python编写的算法比用c编写的要慢很多。对我来说,如果您将代码及其语言视为一个整体,这也是一个算法问题。在python中做同样的事情比c需要更多的机器指令。机器指令序列是一种算法。
x86 指令可以看作是 CPU 内部使用的微代码的高级语言。当 CPU 将 x86 指令解码为带有推测执行的微代码时,将导致显着的性能差异。这也可以归类为算法(增加并发)问题,这不是我在这里想讨论的。
除了算法,还有什么可以使代码在机器上执行缓慢?答案是“数据局部性”,读取和写入数据进行计算需要时间。有很多这样的例子
CPU缓存
GPU架构
分布式映射/减少
堆管理
通过这些例子,我们可以看出为什么异构计算是不可避免的,主流编程语言的编程模型过于简化。
按列迭代矩阵
#include <stdio.h>
#include <stdlib.h>main () {
int i,j;
static int x[4000][4000];
for (i = 0; i < 4000; i++) {
for (j = 0; j < 4000; j++) {
x[j][i] = i + j; }
}}
逐行迭代矩阵
#include <stdio.h>
#include <stdlib.h>main () {
int i,j;
static int x[4000][4000];
for (j = 0; j < 4000; j++) {
for (i = 0; i < 4000; i++) {
x[j][i] = i + j; }
}}
行式版本比列式版本快 3 到 10 倍。当内存地址连续写入时,可以将写入合并为单个请求,以节省往返时间。

根据https://en.wikipedia.org/wiki/CPU_cache,随着 x86 微处理器在 386 中达到 20 MHz 及以上的时钟频率,系统中开始采用少量快速缓存以提高性能。处理器设计最大的问题是内存跟不上处理器的速度。

我们可以看到上面的图表,现代 CPU 每秒可以处理很多数字。保持 cpu 忙碌的理论数据传输速率远高于当前主内存可以提供的带宽。
CPU 和主存储器之间的延迟最终取决于光速。我们必须让内存更靠近 CPU 以降低延迟。但是片上内存(L1/L2/L3缓存)不能太大,否则电路会很长,延迟会很高。
在CPU的设计中,缓存是不可见的,内存是相干的。您不需要处理所有套接字的缓存和内存之间的同步。尽管您确实需要使用内存屏障来声明一个内存地址上的操作序列,就好像它们直接在内存本身上竞争一样。为了实现这一点,CPU 需要高速环/网格来同步套接字之间的缓存。
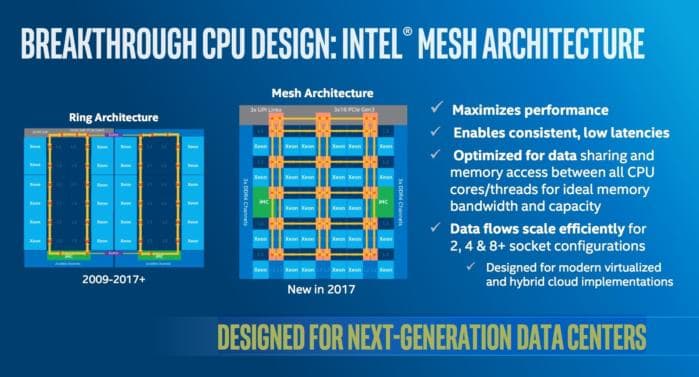
这种编程模型会阻止内核增长。因为数据传输的延迟是不可避免的,所以维持内核之间直接共享内存的错觉成本太高。内存变化需要广播到所有缓存。
GPU架构不同。它通过使“缓存”显式来解决内存延迟问题。它只是您可以使用的另一层内存,而不是称之为“缓存”。
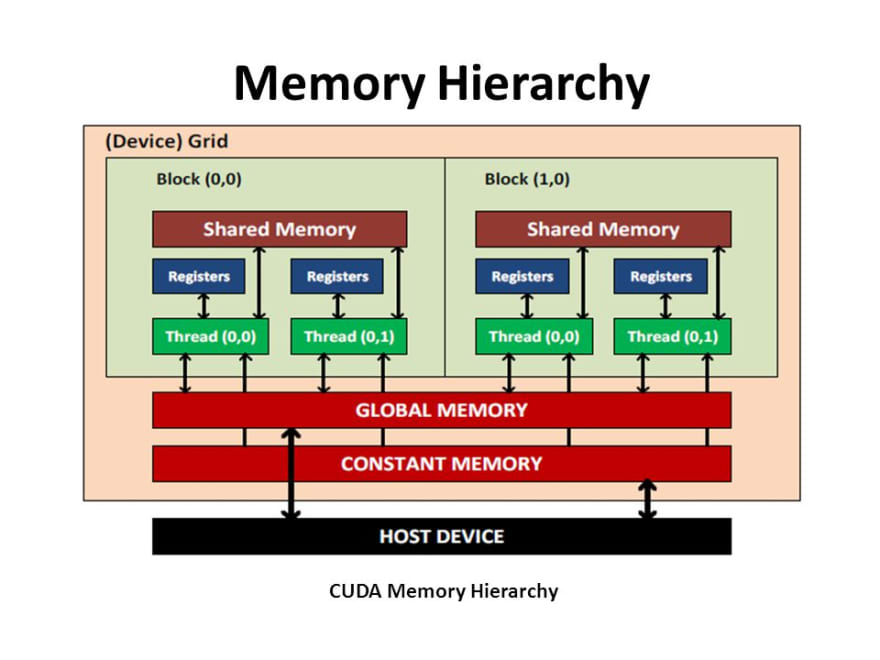
在这种编程模型中,不仅有一个“堆”内存,而且变量需要明确其范围。例如
__global__ void parallel_shared_reduce_kernel(float *d_out, float* d_in){
int myID = threadIdx.x + blockIdx.x * blockDim.x;
int tid = threadIdx.x;
extern __shared__ float sdata[];
sdata[tid] = d_in[myID];
__syncthreads();
//divide threads into two parts according to threadID, and add the right part to the left one,
//lead to reducing half elements, called an iteration; iterate until left only one element
for(unsigned int s = blockDim.x / 2 ; s>0; s>>=1){
if(tid<s){
sdata[tid] += sdata[tid + s];
}
__syncthreads(); //ensure all adds at one iteration are done
}
if (tid == 0){
d_out[blockIdx.x] = sdata[myId];
}}
变量要么没有前缀,__shared__要么__global__。在 CPU 编程中,我们需要猜测缓存是如何工作的。相反,我们可以在 GPU 编程中提问。
Map/Reduce 可以处理分布式的大数据,因为它避免了数据传输在数据原来所在的节点上进行计算

从“map”节点发送到“reduce”节点的数据比原始输入小得多,因为部分计算已经完成。
大堆很难管理。在现代 C++ 或 Rust 中,我们使用所有权来管理内存。本质上,不是使用垃圾收集器将整个堆作为连接的对象图进行管理,而是将堆划分为更小的范围。例如
class widget { private:
gadget g; // lifetime automatically tied to enclosing object public:
void draw(); }; void functionUsingWidget () {
widget w; // lifetime automatically tied to enclosing scope
// constructs w, including the w.g gadget member
…
w.draw();
… } // automatic destruction and deallocation for w and w.g
// automatic exception safety,
// as if "finally { w.dispose(); w.g.dispose(); }"
有很多情况,一个内存地址的生命周期与函数进入/退出和对象构造/销毁很好地对齐。在某些情况下,需要对生命周期进行显式注释
fn substr<'a>(s: &'a str, until: u32) -> &'a str;
'a类似于__shared__CUDA 中的生命周期声明。像 c++ 和 rust 这样的显式生命周期管理是一个极端。Java 和 Go 等多线程安全垃圾收集语言是另一个极端。像 Nim 这样的语言按线程划分内存,线程位于频谱的中间。为了保证不同分区中的内存不会意外共享,跨边界时需要复制内存。同样,最小化内存复制成本是一个数据局部性问题。
JVM 具有垃圾收集功能。它不是静态地注释源代码,而是通过将大堆划分为粗略的代来尝试弄清楚运行时中的内容:

如果我们不首先共享大堆,那么处理堆管理问题会容易得多。在某些情况下,多处理器分片内存是有益的。但在很多情况下,协同定位数据和计算(actor 编程模型)会更容易。
每个时钟的指令增长不是很快。

主内存访问延迟几乎持平

必须处理多个处理器,每个处理器都有自己的内存(异构计算)可能会很普遍。在这种范式中,我们需要确保数据和计算彼此位于同一位置,这是一个明显的趋势。问题是如何正确划分数据和计算,以最小化数据复制或消息传递的方式。
